|
Management-Informationssystem MIS
Inhaltsübersicht
I. MIS-Konzepte und deren historische Entwicklung
II. Data Warehousing und OLAP als Basistechnologien
III. Data Mining zur explorativen Datenanalyse
IV. Eine Architektur für Management-Informationssysteme
I. MIS-Konzepte und deren historische Entwicklung
Für Informationssysteme, die der Managementunterstützung dienen, wurden verschiedene Begriffe geprägt. Diese werden in der Literatur zum Teil unterschiedlich verwendet. Historisch gesehen stammt der Begriff des Management-Informationssystems (MIS) aus den 1960er-Jahren und stand ursprünglich für die Idee, das gesamte Datenvolumen einer Unternehmung den Entscheidungsträgern auf allen Ebenen in geeigneter Form zur Verfügung zu stellen (Oppelt, R. Ulrich G. 1995, S. 106). Darüber hinaus sollten im Rahmen eines so genannten Total Systems Approach Kontroll- und Steuerungsfunktionen unterstützt werden (Oppelt, R. Ulrich G. 1995, S. 106 f.). Diese Ansätze sind aufgrund technischer und konzeptioneller Mängel bei der Umsetzung als gescheitert anzusehen. Der wirtschaftliche Einsatz der Systeme konnte nicht nachgewiesen werden, was unter anderem auch auf eine Überflutung der Entscheidungsträger mit Informationen zurückzuführen ist (Holten, Roland 1999, S. 31). Zudem erfolgte eine aus heutiger Sicht naive Unterordnung organisatorischer und personeller Belange der Informationstechnik (IT) (Oppelt, R. Ulrich G. 1995, S. 106 f.). Folglich wurde die Forderung nach diesen totalen Informationssystemen mit der Zeit aufgegeben. An ihre Stelle traten Ansätze zur Integration verschiedenartiger Teillösungen.
Da die Erwartungen an die frühen MIS nicht erfüllt werden konnten, erfolgte im Laufe der 1970er- und 1980er-Jahre die Entwicklung so genannter Management Reporting Systeme (MRS). MRS dienen der Bedienung strukturierter und standardisierter Informationsbedarfe, wobei insbesondere das Lower und Middle Management mit in der Regel papierbasierten Berichten auf Basis der Daten der operativen Systeme versorgt werden (Knackstedt, Ralf 2004, S. 73 ff.). Diese Systeme werden auch unter dem Oberbegriff Structured Decision Systems zusammengefasst, da der Grad der Strukturiertheit der von diesen Systemen adressierten Problemstellungen als hoch einzustufen ist (Oppelt, R. Ulrich G. 1995, S. 111 f.).
Für diejenigen Systeme, die semi- bis unstrukturierte Problemstellungen des Managements unterstützen sollen, wurde der Begriff des Decision Support System (DSS) geprägt (Mertens, Peter et al. 2001). Im deutschen Sprachgebrauch etablierte sich der Begriff Entscheidungsunterstützungssystem (EUS). Ziel ist es, mit dem Einsatz dieser Systeme die Entscheidungsqualität durch die Ausnutzung existierender Informationen mit Hilfe ausgereifter modellbasierter Methoden zu verbessern (Gorry, G. Anthony/Scott Morton, Michael S. 1971).
Mit Expertensystemen wird das Ziel verfolgt, eine breite Verfügbarkeit von Expertenwissen zu gewährleisten. Die Kombination dieser wissensbasierten Systeme mit Entscheidungsunterstützungssystemen führte in den 1980er-Jahren zum Begriff des Expert Support Systems (XSS).
Werden speziell die oberen Führungsebenen betrachtet, so wird der Begriff der Executive Support Systems (ESS) bzw. Executive Information Systems (EIS) verwendet (Rockart, John F./Treacy, Michael E. 1982). Häufig sind auch die Begriffe Führungs-, Chef- oder Vorstandsinformationssystem zu finden.
Heute wird der Begriff des Management-Informationssystems für all diejenigen Systeme verwendet, die das Management mit Informationen versorgen und somit eine verbesserte Entscheidungsfindung ermöglichen. Insbesondere die flexible und zeitnahe Bedienung der Informationsbedarfe des Managements in immer kürzer werdenden Zeitspannen für strategische Entscheidungen ist heute notwendige Voraussetzung, um im Wettbewerb bestehen zu können. Dabei werden die Mängel, die frühe MIS-Konzeptionen besaßen, vermieden. Dies ist neben der Verfügbarkeit von Basistechnologien wie des Data Warehousing und des Online Analytical Processing (OLAP) auch auf leistungsfähige Hardware, die Vernetzung von Rechnern und eine verbesserte Ergonomie der Software zurückzuführen (Swinotek, Jürgen 1996, S. 133 f.). Darüber hinaus zielen moderne MIS-Konzepte insbesondere darauf ab, dass eine Informationsüberflutung vermieden wird. Insofern kommt der Informationsbedarfsanalyse im Rahmen der Konzeption dieser Systeme eine herausragende Bedeutung zu. MIS setzen sich dabei aus unterschiedlichen Teillösungen zusammen, die sowohl strukturierte als auch semi- bzw. unstrukturierte Entscheidungsprozesse unterstützen. In der Regel existieren mindestens eine Komponente für die Bereitstellung eines Standardberichtswesens sowie ein Analysewerkzeug, das multidimensionale Auswertungen (vgl. II.2.) ermöglicht. Häufig werden diese Lösungen auch unter dem Begriff Business Intelligence zusammengefasst.
II. Data Warehousing und OLAP als Basistechnologien
Grundlage für moderne Führungsinformationssysteme bieten zwei Konzepte bzw. Basistechnologien, die aufeinander aufbauen: das Data Warehousing und das Online Analytical Processing.
1. Data-Warehouse-Prinzip
Ein Data Warehouse ist eine themenorientierte, integrierte, nicht-flüchtige und zeitabhängige Sammlung von Daten zur Unterstützung von Managemententscheidungen (Inmon, William H. 1996, S. 33). Welche Daten gespeichert werden, hängt vom Informationsbedarf der Entscheidungsträger ab. Es handelt sich um eine datenorientierte Vorgehensweise, die im Gegensatz zur prozessorientierten Vorgehensweise transaktionsbasierter operativer Systeme steht (Mucksch, Harry/Behme, Wolfgang 2000, S. 10). Die Daten werden aus unternehmensinternen und unternehmensexternen Quellen extrahiert und im Data Warehouse in einer unternehmensweiten Sicht definitorisch und inhaltlich konsolidiert integriert. Die Datenhaltung erfolgt folglich redundant. Unternehmensinterne Daten stammen vor allem aus operativen Systemen, unternehmensexterne Quellen können z.B. das World Wide Web oder kommerzielle Informations- und Nachrichtendienste sein. Die zeitabhängige Speicherung ist ein wesentliches Merkmal, um aussagekräftige Analysen relevanter Kennzahlen wie z.B. Trendanalysen zu ermöglichen. Entsprechend dürfen historische Daten nicht verändert werden; ein Data Warehouse ist also nicht-flüchtig. Die Daten werden in der Regel nur einmal geladen und dann nicht mehr überschrieben. Zugriffe erfolgen daher nur lesend. Aus betriebswirtschaftlicher Sicht ist ein Data Warehouse eine Integrationsinstanz, deren Aufgabe in der Konsolidierung und Integration von Unternehmensdaten aus verschiedenen organisatorischen und funktionalen Einheiten des Unternehmens zum Zweck der Bedienung der Informationsbedarfe der Entscheidungsträger besteht (Jung, Reinhard/Winter, Robert 2000).
2. OLAP und das multidimensionale Datenmodell
Eine Hauptanwendung von Data Warehouses ist die Analyse archivierter Daten, die als Online Analytical Processing bezeichnet wird und Entscheidungsträgern „ schnelle, interaktive und vielfältige Zugriffe auf relevante und konsistente Informationen “ (Chamoni, Peter/Gluchowski, Peter 2000, S. 334) ermöglichen soll (Vossen, Gottfried 1999, S. 682). Dabei wird deutlich von so genannten Online-Transaction-Processing (OLTP)-Systemen abgegrenzt, deren Aufgabe in der Abwicklung von Transaktionen im Rahmen der operativen Geschäftstätigkeit liegt.
Um diesen Anforderungen gerecht zu werden, muss ein Data Warehouse eine multidimensionale Sicht auf die Daten bereitstellen. Es besteht aus einer Menge von betriebswirtschaftlichen Kennzahlen (z.B. Umsatz, Gewinn etc.) in einem multidimensionalen Kontext (z.B. Filiale, Zeit etc.). Data Warehousing und OLAP sind somit sich gegenseitig ergänzende Konzepte, wobei die OLAP-Tools als das Frontend für den Zugriff auf die im Data Warehouse abgelegten Datenbestände zu betrachten sind (Chamoni, Peter/Gluchowski, Peter 2000, S. 335).
Die technische Umsetzung kann auf verschiedene Art und Weise geschehen. Erfolgt die Abbildung in einem multidimensionalen Datenbankmanagementsystem, spricht man von MOLAP (multidimensionales OLAP), bei einer Umsetzung in relationalen Datenbankmanagementsystemen von ROLAP (relationales OLAP). Gebräuchlich sind heute auch Kombinationen beider Typen. Solche Systeme sind mit dem Begriff HOLAP (hybrides OLAP) belegt.
In den vergangenen Jahren haben sich vor allem relationale Datenbanksysteme am Markt durchsetzen können. Vorteil dieser Systeme gegenüber z.B. multidimensionalen Datenbanksystemen ist in erster Linie die Standardisierung der Abfragesprachen. Die meisten operativen Datenbanksysteme sind ebenfalls relationale Datenbankmanagementsysteme. Entsprechend bietet es sich an, auch Data Warehouses mit Hilfe solcher relationaler Systeme zu realisieren, um eine möglichst einfache Synchronisation der Daten zu ermöglichen. Im Gegensatz dazu bestehen derzeit keine Standards bezüglich der Grundfunktionalität multidimensionaler Datenbanksysteme und es fehlen standardisierte Abfragesprachen und Anwendungs-Programmier-Schnittstellen (API) (Behme, Wolfgang/Holthuis, Jan/Mucksch, Harry 2000, S. 216).
III. Data Mining zur explorativen Datenanalyse
1. Data Mining und Knowledge Discovery in Databases
Neben OLAP als Methode zur deskriptiven Datenanalyse wird auch das Data Mining zu den Aufgaben eines Management-Informationssystems gezählt. Data Mining umfasst Methoden der explorativen Datenanalyse mit dem Ziel, Informationen aus Datenbeständen zu extrahieren. In der Literatur findet sich neben dem Begriff des Data Mining, der sich aufgrund seiner Prägnanz und Kürze etabliert hat, noch der Begriff des Knowledge Discovery in Databases (KDD), der häufig in Form eines Data Mining i.w.S. verwendet wird und damit den gesamten Prozess des Entdeckens von relevantem Wissen in den Datenbeständen umfasst. Um eine Doppelbenennung zu vermeiden, wird im Folgenden KDD als Begriff für den Gesamtprozess und Data Mining als Bezeichnung für den essenziellen Teilprozess des Extrahierens von Mustern aus dem Datenbestand verstanden (Han, Jiawei/Kamber, Micheline 2001, S. 5).
Der KDD-Prozess umfasst dabei grob die vier Phasen der Datenselektion und -extraktion, der Datenaufbereitung und -transformation, den Kernschritt des eigentlichen Data Mining sowie die Evaluation und Präsentation der Ergebnisse (Han, Jiawei/Kamber, Micheline 2001, S. 7). Auch wenn die Phase des Data Mining als der zentrale Schritt des KDD angesehen werden kann, fließen üblicherweise 90% der Arbeit in die umgebenden Phasen der Datenbereitstellung.
2. Knowledge-Discovery-Prozess
Der KDD-Prozess wird nicht lediglich aufgrund der Verfügbarkeit von Daten initiiert. Am Anfang der Analyse steht eine konkrete Fragestellung, für deren Beantwortung die relevanten Daten aus zur Verfügung stehenden Datenbeständen bestimmt und extrahiert werden müssen. Nicht alle extrahierten Daten sind unmittelbar relevant. Daher muss anschließend eine Eingrenzung, eine Selektion, der zu analysierenden Daten vorgenommen werden. Diese kann vertikal und horizontal vorgenommen werden, d.h. es wird entweder die Anzahl der Datensätze oder die Anzahl der zu betrachtenden Attribute eingeschränkt (Han, Jiawei/Kamber, Micheline 2001, S. 148 f.).
Üblicherweise muss im Anschluss an die Extraktion eine Datenaufbereitung stattfinden, da beispielsweise fehlende oder falsche Daten oder Ausreißer und Redundanzen eine Analyse der Daten erschweren. Typische Aufgaben der Datentransformation umfassen die Aggregation von Merkmalen, die Bildung von Summen, Durchschnitten oder Abweichungen von Werten, die Datenumkodierung durch Normierung oder Skalentransformation und eine strukturelle Transformation, sodass die Daten von der Data-Mining-Software verwendet werden können (Fayyad, Usama M. et al. 1996, S. 10; Tan, Pang-Ning/Steinbach, Michael/Kumar, Vipin 2006, S. 45).
Liegen die Daten in einem automatisiert verarbeitbaren Format vor, beginnt der eigentliche Prozess des Data Mining. Es können verschiedene Methoden angewendet werden, die als Ergebnis Regeln, Muster bzw. statistische Auffälligkeiten liefern, welche durch den Empfänger interpretiert werden müssen. Die Form der Muster hängt dabei von der eingesetzten Methode ab. Die zu verwendende Methode wird der Fragestellung entsprechend gewählt, instanziiert und (iterativ) mit Parametern belegt. Es werden dabei Methoden zur Datenbeschreibung und Datenprognose unterschieden. Gängige Methoden der ersten Kategorie umfassen die Assoziationsanalyse, die Clusteranalyse und die Sequenzanalyse. Eine typische Methode zur Prognose ist die Klassifikation (Fayyad, Usama M. et al. 1996, S. 11; Han, Jiawei/Kamber, Micheline 2001, S. 150).
Die Ergebnisse des Data Mining müssen adäquat kommuniziert werden, um für den Anfragesteller einen Nutzen zu erbringen. Ziel der Evaluations- und Präsentationsphase ist es daher, die Ergebnisse in eine dem Entscheidungsträger verständliche (und damit häufig grafische) Form zu bringen, die die komplexen Zusammenhänge einfach darstellt (Tan, Pang-Ning/Steinbach, Michael/Kumar, Vipin 2006, S. 105).
3. Ausgewählte Data-Mining-Methoden
Ziel der Assoziationsanalyse ist es, signifikante Abhängigkeiten zwischen Attributen eines Objekts zu entdecken. Je nachdem, ob eine Kausalität der Zieldaten und der Richtung bekannt sind, können dabei verschiedene Verfahren angewendet werden. Ein typischer Anwendungsfall für die Assoziationsanalyse ist die Warenkorbanalyse. Erweitert man die Assoziationsanalyse um eine zeitliche Dimension, spricht man von der Sequenzanalyse. Ihre Aufgabe ist es, eine Reihe von Objekten in ihrem zeitlichen Zusammenhang zu analysieren, um sowohl Phasen als auch Distanzen zwischen diesen Phasen aufzudecken (Tan, Pang-Ning/Steinbach, Michael/Kumar, Vipin 2006, S. 9; Han, Jiawei/Kamber, Micheline 2001, S. 23).
Die Clusteranalyse zielt darauf ab, Klassen mit möglichst homogenen Objekten zu bilden, wobei die Objekte verschiedener Klassen möglichst heterogen sein sollen. Die Grundannahme ist dabei, dass es im Beobachtungsraum Häufungen von Attributen oder Attributskombinationen gibt und diese nicht gleichverteilt sind. Die Bildung der entsprechenden Cluster geschieht auf Basis dieser Objektattribute. Weiterhin kann ein Objekt auch mehreren Clustern angehören. Ein typisches Beispiel für die Clusteranalyse ist die Bildung von Kundengruppen, die dann gezielt bearbeitet werden können (Fayyad, Usama M. et al. 1996, S. 14 f.; Han, Jiawei/Kamber, Micheline 2001, S. 25).
Bei der Klassifikation handelt es sich um eine Methode zur Datenprognose. Anhand einer Untermenge, einer Stichprobe, wird das System trainiert und ein Modell gebildet, welches Aussagen darüber enthält, welche Attributausprägungen die Zugehörigkeit zu einer Klasse festlegen. Ziel ist es, auf Basis dieser Regeln die Zugehörigkeit von Objekten zu Klassen zu bestimmen und diese automatisiert einzuteilen. Ein Beispiel für Klassifikationssoftware sind E-Mail-Filter-Programme zur Aussortierung sog. Spam-E-Mails (Fayyad, Usama M. et al. 1996, S. 13; Han, Jiawei/Kamber, Micheline 2001, S. 24).
IV. Eine Architektur für Management-Informationssysteme
Abb. 1 zeigt eine exemplarische Architektur für Management-Informationssysteme. Es wird deutlich, dass für eine bedarfsgerechte Managementunterstützung der Einsatz verschiedener der zuvor skizzierten Konzepte nötig ist.
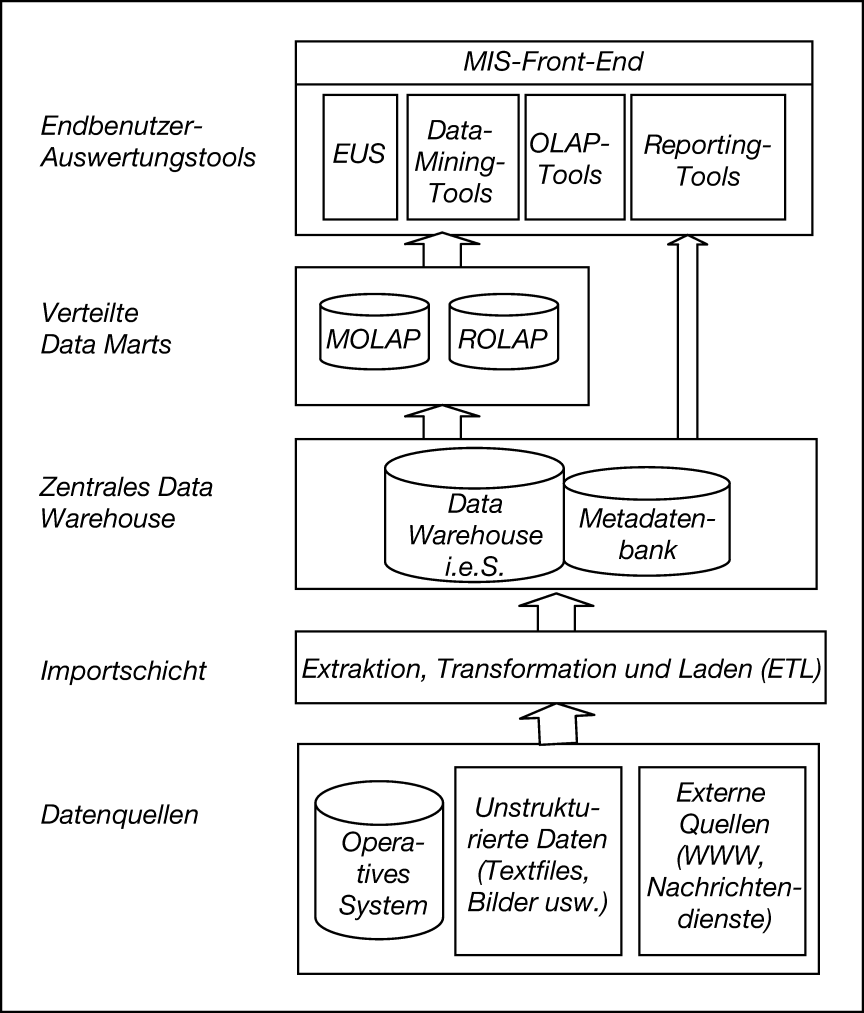
Abb. 1: MIS-Architektur (vgl. Holten, Roland 1999, S. 58)
Aus den operativen Datenquellen, aber auch aus externen Quellen wie dem World Wide Web, werden Daten periodisch oder ereignisgesteuert in ein zentrales Data Warehouse geladen (Kurz, Andreas 1999). Dabei finden auch unstrukturierte Daten wie Bilder oder Texte Berücksichtigung. Gegenstand der Importschicht ist die Überwachung von Änderungen in den Daten der Quellsysteme und die Übertragung der Daten in das zentrale Data Warehouse. Der Prozess des Imports wird üblicherweise als ETL-Prozess (Extraktion, Transformation und Laden) bezeichnet.
Ein wichtiger Bestandteil des zentralen Data Warehouse ist eine Metadatenbank. Hier werden technische und betriebswirtschaftliche Informationen über den Datenbestand abgelegt. Dabei handelt es sich z.B. um Informationen, die die Herkunft der Daten und den Transformationsprozess aber auch den Verdichtungsgrad der Daten beschreiben. Somit richten sich diese Informationen sowohl an Mitarbeiter der IT-Abteilung als auch an Entscheidungsträger (Holten, Roland 1999, S. 46 f.).
In Abhängigkeit von dem zentralen Data Warehouse existieren in der Regel verschiedene Data Marts. Zentrale Data-Warehouse-Lösungen sind in der Praxis schwer umzusetzen (Sapia, Carsten 2001). Zum einen ist dies auf technische Aspekte wie die schlechte Skalierbarkeit großer Systeme zurückzuführen, zum anderen aber auch auf konzeptionelle Aspekte: Aus Projektsicht ist die Umsetzung einzelner Teillösungen in der Regel besser durchführbar als die Konzeption eines zentralen Data Warehouse in einem Schritt. Dazu kommt eine gleichmäßigere Verteilung der Rechen- und Administrationslast auf verschiedene Teilsysteme. Grundsätzlich sind zwei Arten von Data Marts zu unterscheiden (Sapia, Carsten 2001; Böhnlein, Michael 2001, S. 61 ff.): solche, die Sichten auf den integrierten Datenbestand des zugrunde liegenden Data Warehouse darstellen, und solche, die unabhängig voneinander existieren und somit eine isolierte Sicht auf die Quellsysteme darstellen.
Als Frontend-Anwendungen fungieren verschiedene Werkzeuge, die auf die Data Marts bzw. direkt auf das zentrale Data Warehouse zugreifen. Dies sind insbesondere OLAP-Tools, Entscheidungsunterstützungssysteme, Data-Mining-Tools und klassische Berichtswerkzeuge (Reporting-Tools), welche die Bereitstellung eines Standardberichtswesens gewährleisten.
Literatur:
Behme, Wolfgang/Holthuis, Jan/Mucksch, Harry : Umsetzung multidimensionaler Strukturen, in: Das Data Warehouse-Konzept. Architektur – Datenmodelle – Anwendungen, hrsg. v. Mucksch, Harry/Behme, Wolfgang, 4. A., Wiesbaden 2000, S. 215 – 241
Böhnlein, Michael : Konstruktion semantischer Data-Warehouse-Schemata, Wiesbaden 2001
Chamoni, Peter/Gluchowski, Peter : On-Line Analytical Processing (OLAP), in: Das Data Warehouse-Konzept. Architektur – Datenmodelle – Anwendungen, hrsg. v. Mucksch, Harry/Behme, Wolfgang, 4. A., Wiesbaden 2000, S. 333 – 376
Fayyad, Usama M. : Advances in Knowledge Discovery and Data Mining, Cambridge et al. 1996
Gorry, G. Anthony/Scott Morton, Michael S. : A Framework for Management Information Systems, in: Sloan Management Review, Bd. 13, H. 1/1971, S. 55 – 70
Han, Jiawei/Kamber, Micheline : Data Mining: Concepts and Techniques, San Diego 2001
Holten, Roland : Entwicklung von Führungsinformationssystemen. Ein methodenorientierter Ansatz, Wiesbaden 1999
Inmon, William H. : Building the Data Warehouse, 2. A., New York et al. 1996
Jung, Reinhard/Winter, Robert : Data Warehousing: Nutzungsaspekte, Referenzarchitektur und Vorgehensmodell, in: Data Warehousing Strategie, hrsg. v. Jung, Reinhard/Winter, Robert, Berlin et al. 2000, S. 3 – 20
Knackstedt, Ralf : Fachkonzeptionelle Referenzmodellierung einer Managementunterstützung mit qualitativen und quantitativen Daten. Methodische Konzepte zur Konstruktion und Anwendung, Münster 2004
Kurz, Andreas : Data Warehousing. Enabling Technology, Bonn 1999
Mertens, Peter : Grundzüge der Wirtschaftsinformatik, 7. A., Berlin et al. 2001
Mucksch, Harry/Behme, Wolfgang : Das Data Warehouse-Konzept als Basis einer unternehmensweiten Informationslogistik, in: Das Data Warehouse-Konzept. Architektur – Datenmodelle – Anwendungen, hrsg. v. Mucksch, Harry/Behme, Wolfgang, 4. A., Wiesbaden 2000
Oppelt, R. Ulrich G. : Computerunterstützung für das Management: neue Möglichkeiten der computerbasierten Informationsunterstützung oberster Führungskräfte auf dem Weg vom MIS zum EIS?, München 1995
Rockart, John F./Treacy, Michael E. : The CEO Goes On-Line, in: Harvard Business Review, Bd. 60, H. 1/1982, S. 82 – 88
Sapia, Carsten : Data Warehouse, in: Data Warehouse Systeme. Architektur, Entwicklung, Anwendung, hrsg. v. Bauer, Andreas/Günzel, Holger, Heidelberg 2001, S. 56 – 62
Swinotek, Jürgen : Realität und Versprechungen von Führungsinformationssystemen, Frankfurt a. M. 1997
Tan, Pang-Ning/Steinbach, Michael/Kumar, Vipin : Introduction to Data Mining, Boston et al. 2006
Vossen, Gottfried : Datenmodelle, Datenbanksprachen und Datenbank-Management-Systeme, 3. A., München et al. 1999
|
