|
Datenanalyseverfahren
Inhaltsübersicht
I. Allgemeine Bemerkungen
II. Input-/Output-Daten-Charakterisierung für Datenanalyseverfahren und kombinierter Methoden-Einsatz
III. Computerbasierte Entscheidungsunterstützung bei der Marketing-Datenanalyse
I. Allgemeine Bemerkungen
Mit Datenanalyseverfahren werden aus Daten, die zur Beschreibung interessierender Situationen zusammengestellt wurden, neue Informationen erzeugt, die Hilfen für eine adäquate Darstellung, Analyse und Interpretation von ausgewählten Sachverhalten der zugrunde liegenden Situationen liefern sollen.
Datenanalyseverfahren i.w.S. umfassen auch Methoden zur Aufbereitung von Daten, z.B. geeignete Transformationen wie Aggregationen, Überprüfungen auf Konsistenz, Ersetzungen fehlender Daten durch plausible oder statistisch begründete Werte und Reduktionen auf Datenteilmengen. Ein Ziel ist es in diesen Fällen, Voraussetzungen für nachfolgende Anwendungen spezieller Auswertungsmethoden zu überprüfen bzw. zu schaffen. Auch der Wunsch, Prozeduren einzusetzen, die grafische Darstellungen der gefundenen Sachverhalte erlauben, kann zur Benutzung vorgeschalteter Datenaufbereitungsmethoden führen. Aufgrund der bisherigen Charakterisierung von Datenanalyseverfahren ließen sich auch alle statistischen Techniken hier einordnen. Eine solche Vorgehensweise würde aber nicht der Tatsache gerecht, dass der Bereich der klassischen Statistik eine viel ältere Tradition besitzt und sich Datenanalyseverfahren z.T. als Ergänzung zu den Methoden der (mathematischen) Statistik entwickelt haben. Dass eine vorliegende Datengrundlage als Stichprobenrealisation im Rahmen allgemeiner Verteilungsannahmen bzgl. der betrachteten Grundgesamtheit zu sehen ist, tritt bei manchen Anwendungen von Datenanalyseverfahren bewusst in den Hintergrund. Demnach lassen sich eher solche Methoden als Datenanalyseverfahren i.e.S. oder Standard-Verfahren bezeichnen, bei denen man auf eine Betonung statistischer Sichtweisen und wahrscheinlichkeitstheoretischer Grundlagen weitgehend verzichtet. Natürlich ist diese Abgrenzung nicht überschneidungsfrei. Ähnlich wie man zu Bereichen der deskriptiven Statistik einen Theorieteil aus der mathematischen Statistik hinzufügen kann, lassen sich für Standard-Datenanalyseverfahren in vielen Fällen so genannte probabilistische Varianten oder Verallgemeinerungen angeben.
Als Beispiele für Standard-Datenanalyseverfahren können die bekannten hierarchischen Verfahren der Clusteranalyse angeführt werden, zu denen z.B. Verallgemeinerungen, die »pyramidale Strukturen« und »fehlende Werte« berücksichtigen können, entstanden sind (Gaul, W./Schader, M. 1994b).
Die mindestens ebenso gut bekannte Varianzanalyse gehört nach dem zuvor genannten Einteilungsschema zu den Datenanalyseverfahren i.w.S. Hier handelt es sich um klassische Statistik, wobei zur Verwendung des F-Tests Normalverteilungsannahmen unterstellt werden.
Da neben der Clusteranalyse und der Varianzanalyse in diesem Lexikon auch weitere bekannte Beispiele für Datenanalyseverfahren gesondert behandelt werden, z.B. die Conjoint-Analyse, die Faktorenanalyse oder die Kausalanalyse, soll im vorliegenden Beitrag der kombinierte Methoden-Einsatz als wichtiger übergeordneter Aspekt bei der Verwendung von Datenanalyseverfahren diskutiert werden.
II. Input-/Output-Daten-Charakterisierung für Datenanalyseverfahren und kombinierter Methoden-Einsatz
Benutzt man als Kennzeichnung für ein Datenanalyseverfahren zusätzlich die Input-Daten, die für seine Anwendung vorliegen müssen, und die Output-Daten, die durch seinen Einsatz erzeugt werden, so ergeben sich mithilfe solcher Input-/Output-Daten-Charakterisierungen nützliche Beziehungen zwischen vorhandenen Daten und erwünschten Analysezielen. Zu nennen ist hier u.a.:
| - | Verschiedenen Datenanalyseverfahren kann dieselbe Input-/Output-Daten-Charakterisierung zugeordnet sein. | | - | Output-Daten eines Datenanalyseverfahrens können als Input-Daten für ein anderes Datenanalyseverfahren auftreten. | | - | Durch kombinierten Methoden-Einsatz können über Folgen von Datenanalyseverfahren aus vorhandenen Daten über Zwischenergebnisse schließlich Output-Daten für erwünschte Analyseziele generiert werden, die durch die Anwendung eines einzelnen Verfahrens nicht erzeugbar sind. |
In Abb. 1 (s.a. Gaul, W./Baier, D. 1994) ist ausschnittsweise für eine Situation, in der ein kombinierter Methoden-Einsatz durchgeführt werden könnte, ein Beziehungsgeflecht zwischen Input-/Output-Daten und zugehörigen Methoden wiedergegeben worden. Dabei sind Daten durch Rechtecke abgebildet worden. Ellipsenartige Umrandungen beinhalten Datenanalyseverfahren, durch deren Anwendung auf zugehörige vorgelagerte Input-Daten sich (durch Pfeile kenntlich gemachte) Output-Daten bilden lassen, die evtl. zur Weiterverarbeitung durch nachfolgende Methoden benötigt werden. Die Hintereinanderstaffelung der verwendeten Symbole soll andeuten, dass mehrere Datenanalyseverfahren mit derselben Input-/Output-Daten-Charakterisierung bekannt sein können, wodurch sich mehrere Möglichkeiten zur Erzeugung von Output-Daten ergeben. Aus Abb. 1 erkennt man, dass für die Anwendung von Datenanalyseverfahren mit den Bezeichnungen »Kruskal-MDS« und »ein-modale Clusteranalyse (Ward, Ellenbogenkrit.)« Daten zu Unähnlichkeitsbeziehungen zwischen Untersuchungsobjekten bzw. Individuen als Input-Daten benötigt werden, die mittels verschiedener vorgeschalteter Methoden zur Bestimmung von Unähnlichkeitsbeziehungen, die wiederum auf unterschiedliche Input-Daten zugreifen, erzeugt werden können. Abb. 1 zeigt auch, dass für den Einsatz des Datenanalyseverfahren »externe wandernder-Idealpunkt-Analyse« (siehe Gaul, W. 1989 für Erläuterungen zur Modellierung von Marketing-Datenanalyse-Problemen mittels wanderndem [probabilistischem] Idealpunkt oder zum LCJ [Law of Comparative Judgement]-Ansatz von Thurstone) zwei Arten von Input-Daten (Daten zur Repräsentation von Untersuchungsobjekten und Merkmalen sowie individuelle oder segmentspezifische Daten über paarweise Vergleiche von Untersuchungsobjekten) benötigt werden. Hat man solche Daten vorliegen, sind die beliebten gemeinsamen Repräsentationen von (Segmenten von) Individuen, Untersuchungsobjekten und Merkmalen in einem Darstellungsraum (joint space) möglich. Abb. 1 soll dokumentieren, dass für eine moderne Anwendung von Datenanalyseverfahren der kombinierte Methoden-Einsatz, der umfassende Kenntnisse aus vielen Teilgebieten der Datenanalyse erfordert, ein adäquates Instrumentarium ist. Abb. 1 zeigt aber mehr. Durch die vielfältigen Möglichkeiten, Datenanalyseverfahren miteinander zu verbinden, kann ein neues Problem entstehen. Aus den vielen möglichen Vorgehensweisen ist (evtl. unter Berücksichtigung von Nebenbedingungen) eine geeignet oder sogar beste Variante zu wählen.
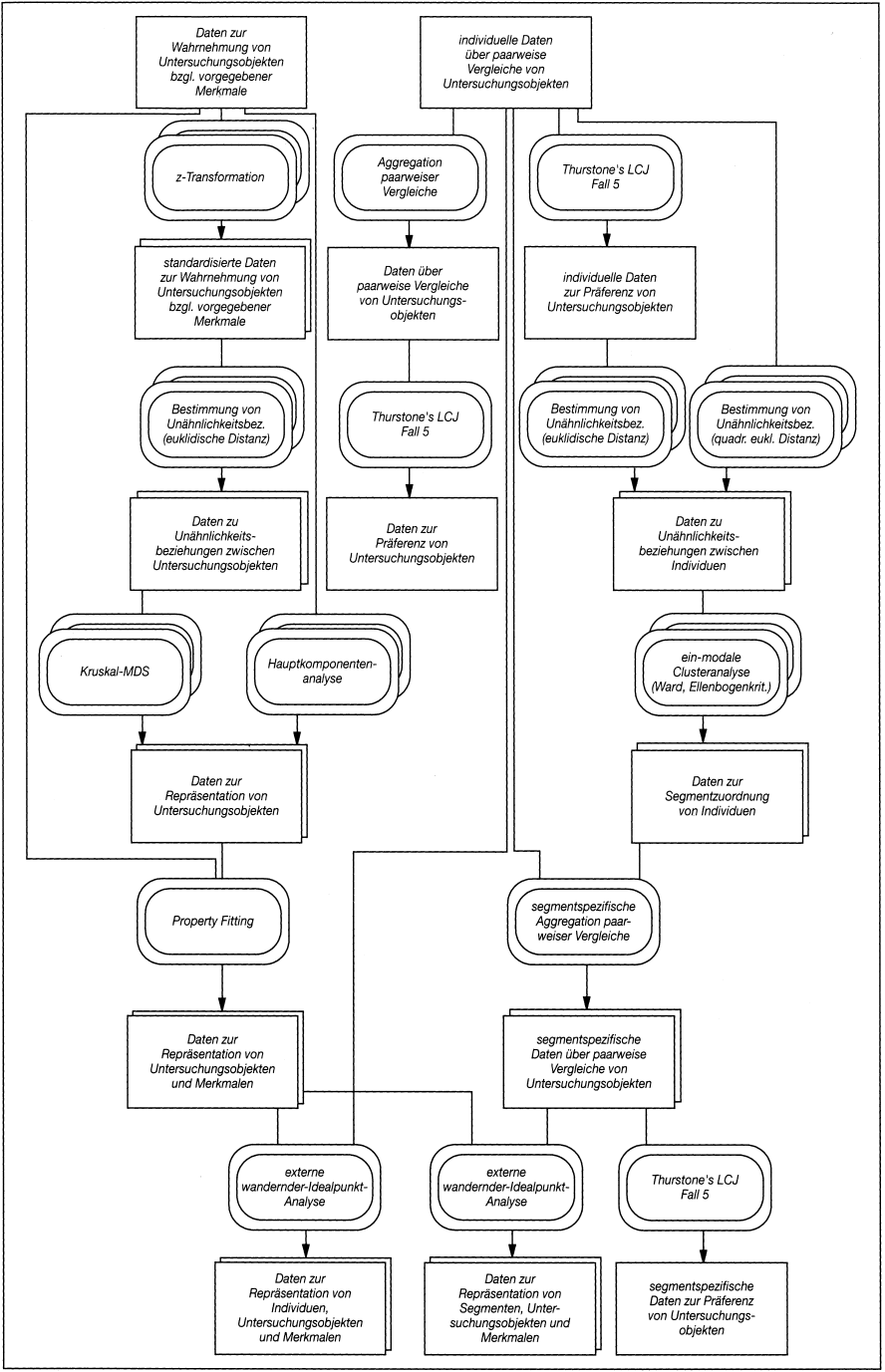
Abb. 1: Beispiel für einen kombinierten Methoden-Einsatz
III. Computerbasierte Entscheidungsunterstützung bei der Marketing-Datenanalyse
Da viele Datenanalyseverfahren in entsprechenden Software-Paketen verfügbar sind und eine moderne Marketing-Datenanalyse in immer stärkerem Maße mit computerbasierter Entscheidungsunterstützung verbunden ist (Gaul, W./Baier, D. 1994), erscheint es naheliegend, nicht nur die Durchführung einzelner Datenanalyseverfahren, sondern auch den kombinierten Methoden-Einsatz durch wissensbasierte Hilfsmittel für mögliche Nutzer zu erleichtern. Eine Einführung in die wissensbasierte Marketing-Datenanalyse findet man in Gaul/Schader (Gaul, W./Schader, M. 1994a). Dabei wird offensichtlich, dass die bisherige Input-/Output-Daten-Charakterisierung nur als umgangssprachliche Beschreibung des dabei zu verwendenden Wissens aufgefasst werden darf. Für den Computer hat eine formale Beschreibung der Input-/Output-Daten und der zugehörigen Datenanalyseverfahren zu erfolgen. Auch muss zwischen der umgangssprachlichen bzw. formalen Beschreibung der Daten und den konkreten Daten, mit denen die Berechnungen durchgeführt werden, unterschieden werden. Haben z.B. Individuen im Rahmen paarweiser Vergleiche bzgl. interessierender Objekte zu verschiedenen Zeitpunkten Bewertungen abgegeben (xijkt = 1, falls Individuum i das Objekt j dem Objekt k zum Zeitpunkt t vorgezogen hat; xijkt = 0, andernfalls), so hat die zugehörige multidimensionale Datentafel X = (xijkt) als konkrete Daten nur Eintragungen mit den Werten 0 oder 1. Die umgangssprachliche Beschreibung für X könnte auf »zeitabhängige, individuelle Daten über paarweise Vergleiche von Untersuchungsobjekten« lauten. Aus Platzgründen werden von den zur formalen Beschreibung von X benötigten Deskriptoren hier nur die Dimensionalität (liefert die Anzahl der in der Datentafel berücksichtigten Dimensionen), die Modalität (gibt die Anzahl der modal unterschiedlichen Mengen an, die über Dateneinträge zueinander in Beziehung stehen), der Datentyp (enthält Hinweise auf die Art der Datenerhebung) und der Skalentyp (beschreibt das Messniveau, auf dem die Daten erhoben werden) erwähnt. Für die Beispiel-Datentafel X ergäbe sich als Ausschnitt aus der formalen Beschreibung (?, Dimensionalität (X) = 4, Modalität (X) = 3, Datentyp (X) = paarweise Vergleiche, Skalentyp (X) = ordinalskaliert, ?). Dass Informationen dieser Art für die computerbasierte Behandlung von Datenanalyse-Problemen hilfreich sind, wird in Gaul/Baier (Gaul, W./Baier, D. 1994) und Gaul/Schader (Gaul, W./Schader, M. 1994a) ausführlicher erläutert.
Literatur:
Gaul, W. : Probabilistic Choice Behaviour Models And Their Combination With Additional Tools Needed For Applications To Marketing, in: New Developments in Psychological Choice Modeling, hrsg. v. Soete, G. De/Feger, H./Klauer, K. C., North-Holland 1989, S. 317 – 337
Gaul, W./Baier, D. : Marktforschung und Marketing Management, 2. A., München et al. 1994
Gaul, W./Schader, M. : Wissensbasierte Marketing-Daten-Analyse: Das WIMDAS-Projekt, Frankfurt a.M. et al. 1994a
Gaul, W./Schader, M. : Pyramidal Classification Based On Incomplete Dissimilarity Data, in: Journal of Classification, 1994b
|
